Azure VM スケールセットでヘルスモニタリングを有効化する設定手順

このブログシリーズ 「クラウドセキュリティ 実践集」 では、一般的なセキュリティ課題を取り上げ、「なぜ危険なのか?」 というリスクの解説から、 「どうやって直すのか?」 という具体的な修復手順(コンソール、Azure CLI、Terraformなど)まで、分かりやすく解説します。
この記事では、Azure VM スケールセットでヘルスモニタリングが有効化されていない問題について、リスクと対策を解説します。
ポリシーの説明
Azure Virtual Machine Scale Sets (VMSS) において、インスタンスの健全性を継続的に監視するヘルスモニタリング機能が有効化されていない場合、異常なインスタンスの自動検出と修復ができません。
ヘルスモニタリングには以下の3つの主要な方法があります:
- Application Health Extension: VM内部からアプリケーションの状態を直接監視(推奨)
- Load Balancer Health Probes: ロードバランサーを介した外部からの監視
- Application Gateway Health Probes: Application Gatewayを使用した高度な監視
これらの機能を有効化することで、高可用性を実現し、問題のあるインスタンスを自動的に修復することが可能になります。
修復方法
コンソールでの修復手順
Azure コンソールを使用して、VM スケールセットのヘルスモニタリングを有効化します。
1. Application Health Extension を使用する方法(推奨)
事前準備
- アプリケーションにヘルスチェックエンドポイントを実装(HTTP 200 OKを返す)
- ファイアウォール/NSGでヘルスチェックポートを許可
設定手順
- Azure Portal にログインし、「仮想マシン スケール セット」を選択
- 対象のスケールセットを選択
- 左側メニューから「拡張機能 + アプリケーション」を選択
- 「追加」をクリックし、「Application Health」を選択
- 以下の設定を行います:
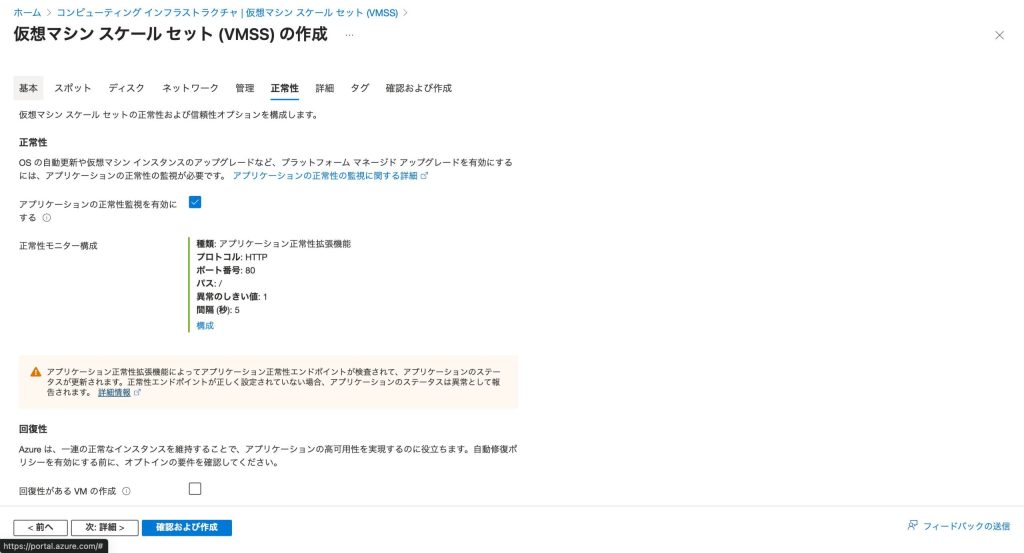
- プロトコル:
- HTTP/HTTPS: RESTful APIの場合(推奨)
- TCP: データベースやメッセージングサービスの場合
- ポート:
- Webアプリ: 80 (HTTP) または 443 (HTTPS)
- APIサービス: 8080, 3000 など
- パス (HTTP/HTTPSの場合):
- 推奨:
/healthまたは/api/health - 詳細チェック:
/health/ready(準備完了),/health/live(生存確認)
- 推奨:
- 間隔:
- 本番環境: 5-10秒
- 開発環境: 30-60秒
- プローブ数:
- 推奨: 2-3回(連続失敗で異常判定)
- 「作成」をクリックして拡張機能を追加
2. 自動修復ポリシーの設定
- スケールセットの「設定」セクションから「正常性と修復」を選択
- 「インスタンスの修復」セクションで以下を設定:
- 自動修復を有効にする: オンに設定
- 猶予期間の設定ガイドライン:
- 新規インスタンス: 30分(初期化完了までの時間を確保)
- 既存インスタンス: 5-10分(一時的な問題を除外)
- アップグレード中: 60分以上(ローリングアップデートを考慮)
- 修復アクション:
- Reimage: OSディスクを再作成(データディスクは保持)
- Restart: インスタンスを再起動
- Delete and Replace: インスタンスを完全に置き換え(推奨)
- 「保存」をクリック
3. Load Balancer Health Probes を使用する方法
適用シナリオ
- 既存のLoad Balancerを使用している場合
- 外部からのアクセス可能性を確認したい場合
- L4レベルのヘルスチェックで十分な場合
設定手順
- スケールセットに関連付けられた Load Balancer を選択
- 「正常性プローブ」を選択し、「追加」をクリック
- 以下の設定を行います:
- 名前:
health-probe-[protocol]-[port](例: health-probe-http-80) - プロトコル選択:
- HTTP/HTTPS: Webアプリケーション
- TCP: データベース、キャッシュサーバー
- ポート:
- Standard Load Balancer: 1-65535
- Basic Load Balancer: 1-65535 (制限あり)
- パス (HTTP/HTTPS):
- 健全性:
/healthまたは/api/health - 詳細状態:
/health/detailed
- 健全性:
- 詳細設定:
- プローブ間隔: 5秒 (最小) – 30秒 (推奨: 15秒)
- 異常しきい値: 2-10回 (推奨: 2回)
- 成功しきい値: 2回 (復帰判定)
- 名前:
- スケールセットの設定で、作成した正常性プローブを関連付け
最後に
この記事では、Azure VM スケールセットでヘルスモニタリングを有効化する設定手順について、リスクと対策を解説しました。
ヘルスモニタリングの有効化により、異常なインスタンスの自動検出と修復が可能になり、サービスの可用性が大幅に向上します。Application Health Extension や Load Balancer Health Probes を適切に設定することで、運用負荷を削減し、ビジネス継続性を確保できます。
この問題の検出は弊社が提供するSecurifyのCSPM機能で簡単に検出及び管理する事が可能です。 運用が非常に楽に出来る製品になっていますので、ぜひ興味がある方はお問い合わせお待ちしております。 最後までお読みいただきありがとうございました。この記事が皆さんの役に立てば幸いです。
参考情報
- Azure VM スケール セットの概要 | Microsoft Learn
- Application Health Extension | Microsoft Learn
- 自動インスタンス修復 | Microsoft Learn
- Load Balancer ヘルス プローブ | Microsoft Learn
- VMSS のベスト プラクティス | Microsoft Learn
- Azure Well-Architected Framework – 信頼性 | Microsoft Learn
- Terraform azurerm_linux_virtual_machine_scale_set | Terraform Registry
- Terraform azurerm_windows_virtual_machine_scale_set | Terraform Registry
- Azure セキュリティ ベスト プラクティス | Microsoft Learn