GKE Cloud Monitoringの有効化について

このブログシリーズ 「クラウドセキュリティ 実践集」 では、一般的なセキュリティ課題を取り上げ、「なぜ危険なのか?」 というリスクの解説から、 「どうやって直すのか?」 という具体的な修復手順(コンソール、gcloud CLI、Terraformなど)まで、分かりやすく解説します。
この記事では、GKEクラスタでCloud Monitoringが無効化されている場合の深刻なセキュリティリスクと、適切な設定方法について詳細に解説します。

ポリシーの説明
GKE(Google Kubernetes Engine)のCloud Monitoring機能は、クラスタの健全性とセキュリティを維持するための中核的な機能です。この機能により、以下の重要なメトリクスが収集・分析されます:
- リソースメトリクス:CPU、メモリ、ディスクI/O、ネットワーク使用率
- Kubernetesメトリクス:Podステータス、レプリカ数、コンテナ再起動回数
- セキュリティメトリクス:APIサーバーエラー率、認証失敗数、不審なアクセスパターン
- SLO/SLIメトリクス:可用性、レイテンシ、エラー率
修復方法
コンソールでの修復手順
Google Cloud コンソールを使用して、GKEクラスタでCloud Monitoringを有効化します。
- Google Cloud Consoleにログインし、「Kubernetes Engine」→「クラスタ」を選択します
- Cloud Monitoringを有効化したいクラスタ名をクリックします
- 「編集」ボタン(鉛筆アイコン)をクリックします
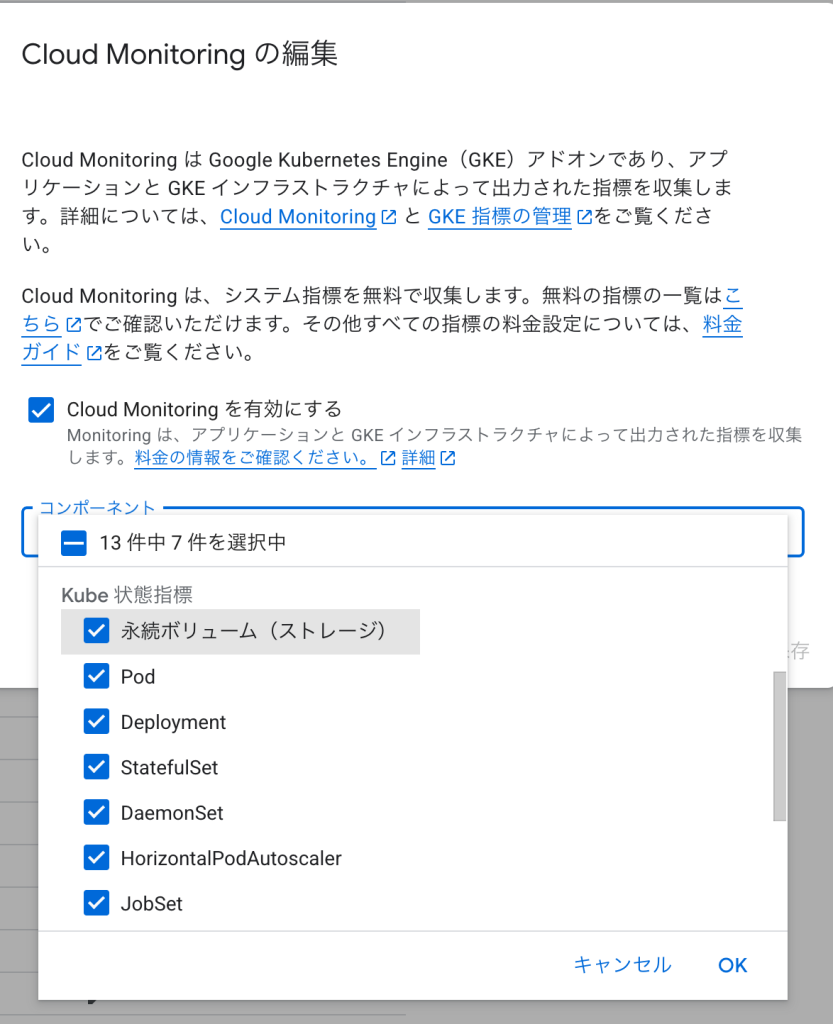
- Cloud Monitoringの設定で以下を確認・変更します:
- 「システムとワークロードのロギングとモニタリング」を選択
- または「システムのロギングとモニタリング」を選択(最低限の推奨設定)

- 「保存」をクリックして変更を適用します
- クラスタの更新が完了するまで待機します(通常5-10分、ノード数により変動)
注意事項:
- クラスタ更新中もワークロードは継続して動作します
- ノードの再作成は発生しません
- 既存のメトリクスデータには影響しません
gcloud CLIでの修復手順
# 1. 環境変数の設定
export CLUSTER_NAME="your-cluster-name"
export REGION="asia-northeast1" # または適切なリージョン
export PROJECT_ID="your-project-id"
# 2. 現在の設定を確認
gcloud container clusters describe ${CLUSTER_NAME} \
--region=${REGION} \
--project=${PROJECT_ID} \
--format="yaml(monitoringConfig)"
# 3. Cloud Monitoringを有効化(システムとワークロード両方)
gcloud container clusters update ${CLUSTER_NAME} \
--region=${REGION} \
--project=${PROJECT_ID} \
--enable-cloud-monitoring \
--monitoring=SYSTEM,WORKLOAD
# 4. Managed Prometheusも有効化する場合
gcloud container clusters update ${CLUSTER_NAME} \
--region=${REGION} \
--project=${PROJECT_ID} \
--enable-managed-prometheus
# 5. 更新状態の確認
gcloud container operations list \
--region=${REGION} \
--filter="status!=DONE AND targetLink:${CLUSTER_NAME}" \
--format="table(name,operationType,status,startTime)"
# 6. 更新完了後の確認
gcloud container clusters describe ${CLUSTER_NAME} \
--region=${REGION} \
--format="table(
monitoringConfig.componentConfig.enableComponents[]:label=ENABLED_COMPONENTS
)"
既存クラスタでの追加設定
- クラスタの詳細ページで「機能」タブを確認
- 「Cloud Monitoring」が「有効」になっていることを確認
- 「ワークロード」タブでメトリクスが表示されることを確認(反映まで5-10分)
Terraformでの修復手順
GKEクラスタでCloud Monitoringを有効にするTerraformコードと、主要な設定ポイントを説明します。
# GKEクラスタでCloud Monitoringを有効化する設定
resource "google_container_cluster" "primary" {
name = "secure-gke-cluster"
location = var.region
# 初期ノード数(後でnode_poolで管理)
initial_node_count = 1
# Cloud Monitoringの有効化設定
monitoring_config {
# 有効化するコンポーネントを指定
enable_components = [
"SYSTEM_COMPONENTS", # システムコンポーネントの監視(必須)
"WORKLOADS", # ワークロードの監視(推奨)
"APISERVER", # API Serverメトリクス(v1.27以降)
"CONTROLLER_MANAGER", # Controller Managerメトリクス(v1.27以降)
"SCHEDULER" # Schedulerメトリクス(v1.27以降)
]
# Managed Prometheusの有効化(推奨)
managed_prometheus {
enabled = true
}
}
# 従来の監視設定(後方互換性のため)
monitoring_service = "monitoring.googleapis.com/kubernetes"
# Loggingも合わせて有効化(推奨)
logging_config {
enable_components = [
"SYSTEM_COMPONENTS",
"WORKLOADS"
]
}
# ネットワーク設定
network = google_compute_network.vpc.name
subnetwork = google_compute_subnetwork.subnet.name
# ワークロードアイデンティティの有効化(推奨)
workload_identity_config {
workload_pool = "${var.project_id}.svc.id.goog"
}
# その他のセキュリティ設定
private_cluster_config {
enable_private_nodes = true
enable_private_endpoint = false
master_ipv4_cidr_block = "172.16.0.0/28"
}
ip_allocation_policy {
cluster_secondary_range_name = "gke-pods"
services_secondary_range_name = "gke-services"
}
}
# ノードプール設定
resource "google_container_node_pool" "primary_nodes" {
name = "primary-node-pool"
location = var.region
cluster = google_container_cluster.primary.name
node_count = var.node_count
node_config {
preemptible = false
machine_type = var.machine_type
# サービスアカウント設定
service_account = google_service_account.gke_node.email
oauth_scopes = [
"<https://www.googleapis.com/auth/cloud-platform>",
"<https://www.googleapis.com/auth/monitoring>", # 監視権限
"<https://www.googleapis.com/auth/monitoring.write>", # メトリクス書き込み権限
"<https://www.googleapis.com/auth/logging.write>" # ログ書き込み権限
]
# メタデータ設定
metadata = {
disable-legacy-endpoints = "true"
}
# シールドインスタンス設定
shielded_instance_config {
enable_secure_boot = true
enable_integrity_monitoring = true
}
# ワークロードアイデンティティ
workload_metadata_config {
mode = "GKE_METADATA"
}
}
# 自動修復・アップグレード
management {
auto_repair = true
auto_upgrade = true
}
}
# ノード用サービスアカウント
resource "google_service_account" "gke_node" {
account_id = "gke-node-sa"
display_name = "GKE Node Service Account"
project = var.project_id
}
# 必要なIAMロール
resource "google_project_iam_member" "gke_node_monitoring" {
project = var.project_id
role = "roles/monitoring.metricWriter"
member = "serviceAccount:${google_service_account.gke_node.email}"
}
resource "google_project_iam_member" "gke_node_logging" {
project = var.project_id
role = "roles/logging.logWriter"
member = "serviceAccount:${google_service_account.gke_node.email}"
}
# アラートポリシーの例
resource "google_monitoring_alert_policy" "high_cpu" {
display_name = "GKE High CPU Usage"
combiner = "OR"
conditions {
display_name = "CPU usage above 80%"
condition_threshold {
filter = "resource.type = \"k8s_node\" AND metric.type = \"kubernetes.io/node/cpu/allocatable_utilization\""
duration = "300s"
comparison = "COMPARISON_GT"
threshold_value = 0.8
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
notification_channels = [google_monitoring_notification_channel.email.name]
documentation {
content = "CPU使用率が80%を超えています。スケーリングを検討してください。"
}
}
# メモリリーク検知アラート
resource "google_monitoring_alert_policy" "memory_leak" {
display_name = "GKE Memory Leak Detection"
combiner = "OR"
conditions {
display_name = "Memory usage increasing trend"
condition_threshold {
filter = "resource.type = \"k8s_pod\" AND metric.type = \"kubernetes.io/pod/memory/working_set_bytes\""
duration = "1800s" # 30分間
comparison = "COMPARISON_GT"
threshold_value = 0.85 # 85%以上
aggregations {
alignment_period = "300s"
per_series_aligner = "ALIGN_RATE"
cross_series_reducer = "REDUCE_MEAN"
group_by_fields = ["resource.pod_name"]
}
}
}
alert_strategy {
notification_rate_limit {
period = "3600s" # 1時間に1回まで
}
}
}
# クリプトマイニング検知アラート
resource "google_monitoring_alert_policy" "crypto_mining_detection" {
display_name = "Possible Crypto Mining Activity"
combiner = "AND"
conditions {
display_name = "Sustained high CPU usage"
condition_threshold {
filter = "resource.type = \"k8s_pod\" AND metric.type = \"kubernetes.io/pod/cpu/core_usage_time\""
duration = "3600s" # 1時間継続
comparison = "COMPARISON_GT"
threshold_value = 0.90 # 90%以上
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_RATE"
}
}
}
conditions {
display_name = "Low network activity"
condition_threshold {
filter = "resource.type = \"k8s_pod\" AND metric.type = \"kubernetes.io/pod/network/sent_bytes_count\""
duration = "3600s"
comparison = "COMPARISON_LT"
threshold_value = 1000000 # 1MB/s未満
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
# 通知チャンネル
resource "google_monitoring_notification_channel" "email" {
display_name = "Email Notification"
type = "email"
labels = {
email_address = var.alert_email
}
}
# Slack通知チャンネル
resource "google_monitoring_notification_channel" "slack" {
display_name = "Slack Alert Channel"
type = "slack"
labels = {
channel_name = "#alerts-gke"
}
user_labels = {
severity = "critical"
}
sensitive_labels {
url = var.slack_webhook_url
}
}
# カスタムダッシュボード
resource "google_monitoring_dashboard" "gke_security" {
dashboard_json = jsonencode({
displayName = "GKE Security Monitoring Dashboard"
mosaicLayout = {
columns = 12
tiles = [
{
width = 6
height = 4
widget = {
title = "Suspicious CPU Usage Patterns"
xyChart = {
dataSets = [{
timeSeriesQuery = {
timeSeriesFilter = {
filter = "resource.type=\"k8s_pod\" metric.type=\"kubernetes.io/pod/cpu/core_usage_time\""
aggregation = {
alignmentPeriod = "60s"
perSeriesAligner = "ALIGN_RATE"
crossSeriesReducer = "REDUCE_TOP"
sortOrder = "DESCENDING"
limit = 10
}
}
}
}]
}
}
},
{
width = 6
height = 4
widget = {
title = "Memory Usage Trends"
xyChart = {
dataSets = [{
timeSeriesQuery = {
timeSeriesFilter = {
filter = "resource.type=\"k8s_pod\" metric.type=\"kubernetes.io/pod/memory/working_set_bytes\""
aggregation = {
alignmentPeriod = "300s"
perSeriesAligner = "ALIGN_MEAN"
}
}
}
}]
}
}
}
]
}
})
}
主要な設定ポイント
- monitoring_config: 監視する詳細なコンポーネントを指定
- SYSTEM_COMPONENTS: kubelet、kube-proxy等の基本メトリクス
- WORKLOADS: Pod、Container、Deploymentのメトリクス
- managed_prometheus: Prometheusベースの高度な監視を有効化(月額$0.15/百万サンプル)
- 適切なOAuthスコープ: ノードに監視関連の権限を付与
- IAMロール: メトリクス書き込み権限の付与(roles/monitoring.metricWriter必須)
- アラートポリシー: 異常検知のための自動アラート設定
まとめ
この記事では、GKEクラスタでCloud Monitoringが無効化されている場合の深刻なリスクと対策について解説しました。Cloud Monitoringを適切に設定することで、リソース枯渇の予防などが可能になります。
現在ではManaged Prometheusの選択肢もあり、よりカスタマイズしたカスタムメトリクスの収集なども可能になりますので必要に応じた使い分けをしていくことが出来ます。
この問題の検出は弊社が提供するSecurifyのCSPM機能で簡単に検出及び管理する事が可能です。 運用が非常に楽に出来る製品になっていますので、ぜひ興味がある方はお問い合わせお待ちしております。 最後までお読みいただきありがとうございました。この記事が皆さんの役に立てば幸いです。
CSPMについてはこちらで解説しております。併せてご覧ください。

参考情報
関連ドキュメント
公式ドキュメント
- Google Cloud Monitoring公式ドキュメント
- GKE監視のベストプラクティス
- Managed Service for Prometheusドキュメント
- アラートポリシーの作成方法
- メトリクスの料金計算
技術ブログ・事例
関連するSecurifyブログ記事