GKEノードのデフォルトサービスアカウントを使用しないための設定

このブログシリーズ 「クラウドセキュリティ 実践集」 では、一般的なセキュリティ課題を取り上げ、「なぜ危険なのか?」 というリスクの解説から、 「どうやって直すのか?」 という具体的な修復手順(コンソール、GCP CLI、Terraformなど)まで、分かりやすく解説します。
この記事では、Google Kubernetes Engine (GKE) ノードでカスタムサービスアカウントを使用する設定手順について、具体的なセキュリティリスクと実践的な対策方法を解説します。デフォルトのCompute Engineサービスアカウントの使用は、多くの組織で見落とされがちなセキュリティリスクですが、適切に対処することで大幅なセキュリティ向上が期待できます。

ポリシーの説明
GKEクラスターのノードでは、デフォルトでプロジェクトのCompute Engineデフォルトサービスアカウント([PROJECT_NUMBER]-compute@developer.gserviceaccount.com)が使用されます。このデフォルトサービスアカウントは、プロジェクトの編集者(Editor)ロールを持っており、プロジェクト内のほぼすべてのリソースに対して読み書きアクセス権が付与されています。
セキュリティのベストプラクティスでは、最小権限の原則(Principle of Least Privilege)に基づいて、ノードには必要最小限の権限のみを持つカスタムサービスアカウントを使用することが強く推奨されています。
リスク
GKEノードがデフォルトのCompute Engineサービスアカウントを使用している場合、以下のセキュリティリスクが発生します:
- 過剰な権限付与:
- デフォルトサービスアカウントはプロジェクトレベルのEditor権限を保持
- Compute Engine、Cloud Storage、BigQueryなど、プロジェクト内のほぼすべてのリソースへの読み書きアクセスが可能
- サービスアカウントの作成は可能だが、IAMポリシーの変更はできない(Owner権限またはroles/iam.securityAdminが必要)
- コンテナ脱出時の影響範囲拡大:
- PodからホストVMへの脱出に成功した場合、攻撃者はプロジェクト全体へのアクセスを獲得
- 他のGKEクラスター、VMインスタンス、データベースなどへの不正アクセスが可能
- 機密データの窃取や削除のリスク
- 権限昇格のリスク:
- Editor権限でサービスアカウントは作成できるが、そのサービスアカウントへの権限付与は不可
- ただし、既存のリソースへの広範なアクセスにより、間接的な権限昇格の可能性
- 設定ミスや脆弱性を悪用した攻撃の起点となるリスク
なぜデフォルトサービスアカウントは危険なのか
デフォルトサービスアカウントがもたらす5つの主要なセキュリティリスク:
- 広範囲なリソースアクセス: プロジェクト内のほぼすべてのGCPリソースへの読み書き権限
- コンテナ脱出時の被害拡大: Pod→ノード→プロジェクト全体への攻撃経路
- 最小権限の原則違反: 必要以上の権限による潜在的セキュリティホール
修復方法
移行前チェックリスト
前提条件の確認
修復を行う前に、以下を確認してください:
- GKEクラスターに対する
container.adminまたはcontainer.clusterAdminロールを保持していること - サービスアカウントの作成権限(
iam.serviceAccounts.create)を保持していること - IAMポリシーの編集権限(
resourcemanager.projects.setIamPolicy)を保持していること - ワークロードの中断に備えたメンテナンスウィンドウが確保されていること
- kubectl CLIがインストールされ、クラスターへのアクセスが可能なこと
現状の確認方法
まず、現在のクラスターがデフォルトサービスアカウントを使用しているか確認します:
# クラスター一覧とノードプールの確認
gcloud container clusters list
# 特定クラスターのノードプール詳細確認
gcloud container node-pools describe [NODEPOOL_NAME] \
--cluster=[CLUSTER_NAME] \
--zone=[ZONE] \
--format="value(config.serviceAccount)"
# デフォルトSAを使用している全ノードプールの検出
for cluster in $(gcloud container clusters list --format="value(name,zone)"); do
name=$(echo $cluster | cut -d' ' -f1)
zone=$(echo $cluster | cut -d' ' -f2)
echo "Checking cluster: $name in $zone"
gcloud container node-pools list --cluster=$name --zone=$zone \
--format="table(name,config.serviceAccount)" | grep -E "compute@developer.gserviceaccount.com|default"
done
コンソールでの修復手順
⚠️ 重要: 既存のノードプールのサービスアカウントは変更できません。必ず新しいノードプールを作成してください。
Google Cloud コンソールを使用して、GKEノードでカスタムサービスアカウントを使用するように設定します。
ステップ1: カスタムサービスアカウントの作成
- Google Cloud コンソールにログインします
- 左側のナビゲーションメニューから「IAMと管理」→「サービスアカウント」を選択します
- 画面上部の「サービスアカウントを作成」をクリックします
- 以下の情報を入力します:
- サービスアカウント名:
gke-node-sa-[クラスター名](例:gke-node-sa-production) - サービスアカウントID: 自動生成されたIDを使用するか、カスタムIDを指定
- 説明: 「GKEノード用のカスタムサービスアカウント – 最小権限で構成」
- サービスアカウント名:
- 「作成して続行」をクリックします
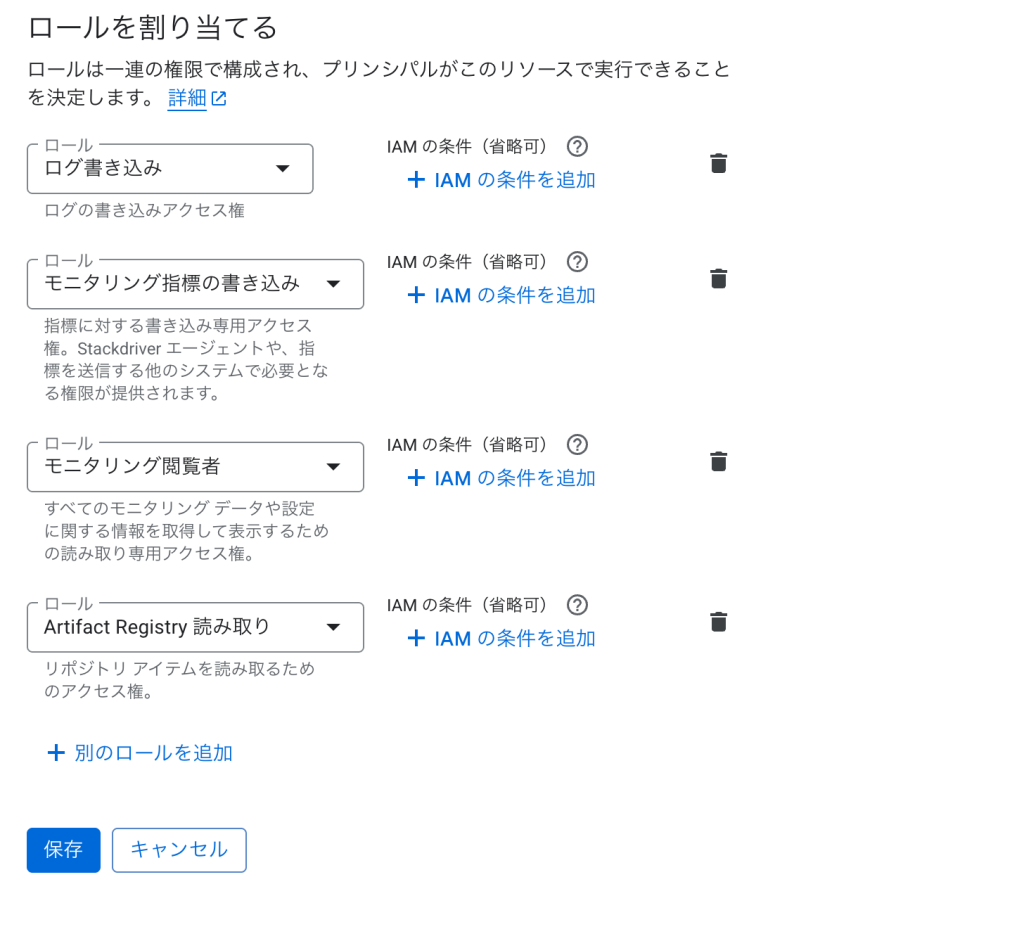
ステップ2: 必要な権限の付与
- 「このサービス アカウントにロールを付与」セクションで、利用する最小権限のみを付与してください。なお、以下は必須で必要となります。
必須ロール:
roles/logging.logWriter– Cloud Loggingへのログ書き込みroles/monitoring.metricWriter– Cloud Monitoringへのメトリクス書き込みroles/monitoring.viewer– モニタリング情報の読み取り
コンテナイメージの取得用(使用するレジストリに応じて選択):
- Artifact Registry使用時:
roles/artifactregistry.reader

- 各ロールを追加する際は、「ロールを選択」ドロップダウンから選択するか、検索ボックスにロール名を入力します
- すべてのロールを追加したら、「続行」をクリックし、「完了」をクリックします
ステップ3: 既存のノードプールの更新(新しいノードプールの作成)
重要: 既存のノードプールのサービスアカウントは変更できません。新しいノードプールを作成し、ワークロードを移行した後、古いノードプールを削除する必要があります。
- 「Kubernetes Engine」→「クラスター」に移動します
- 対象のクラスターをクリックします
- 「ノードプール」タブを選択します
- 「ノードプールを追加」をクリックします
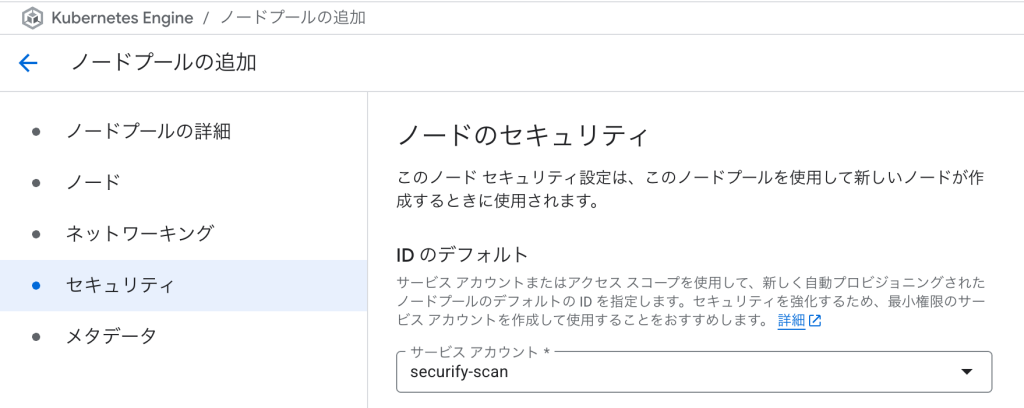
- 「セキュリティ」セクションで:
- サービスアカウント: 作成したカスタムサービスアカウントを選択

- アクセススコープ: 「アクセス スコープを設定」を選択し、以下のスコープのみを有効化:
- 「Stackdriver Logging API」 – ログ書き込み用
- 「Stackdriver Monitoring API」 – メトリクス書き込み用
- 「Storage」を「読み取り専用」に設定 – コンテナイメージ取得用(Container Registry使用時のみ)
💡 Workload Identity推奨: Workload Identityを使用する場合は、ノードのスコープは最小限にし、アプリケーション固有の権限はPodレベルで管理します。これにより、より細かい権限制御が可能になります。
- その他の設定は既存のノードプールと同じにします
- 「作成」をクリックします
ステップ4: ワークロードの移行
- Cloud Shellまたはローカル端末からkubectlを使用して、新しいノードプールが作成されたことを確認:
# クラスターへの認証情報を取得 gcloud container clusters get-credentials [クラスター名] --zone=[ゾーン名] # ノードプールの確認 kubectl get nodes -o wide --show-labels | grep gke-nodepool - 既存のノードプールからワークロードを移行:
# 既存のノードプール名を確認 OLD_NODEPOOL="[既存のノードプール名]" # 既存のノードプールにcordonを設定(新規Podスケジューリングを防止) kubectl cordon -l cloud.google.com/gke-nodepool=$OLD_NODEPOOL # 既存のノードからPodを退避(段階的に実施することを推奨) for node in $(kubectl get nodes -l cloud.google.com/gke-nodepool=$OLD_NODEPOOL -o name); do echo "Draining $node..." kubectl drain $node --ignore-daemonsets --delete-emptydir-data --force --grace-period=300 sleep 30 # ノード間での適切な間隔を確保 done - すべてのPodが新しいノードプールに移行されたことを確認:
# ノードの状態確認 kubectl get nodes -o wide # Podの配置確認 kubectl get pods --all-namespaces -o wide | grep -v "NODE" # 問題があるPodの確認 kubectl get pods --all-namespaces | grep -v "Running\|Completed"
ステップ5: 古いノードプールの削除
- Google Cloud コンソールで、クラスターの「ノードプール」タブに戻ります
- 古いノードプール(デフォルトサービスアカウントを使用)の横にある削除アイコンをクリックします
- 確認ダイアログで「削除」をクリックします
gcloud CLIでの修復手順(所要時間:約10分)
Google Cloud CLIを使用してカスタムサービスアカウントを作成し、GKEノードプールを更新します。
# 1. 現在のクラスターとノードプールの確認
gcloud container clusters list
gcloud container node-pools list --cluster=[クラスター名] --zone=[ゾーン名]
# 2. カスタムサービスアカウントの作成
gcloud iam service-accounts create gke-node-sa-[クラスター名] \
--display-name="GKE Node Service Account for [クラスター名]" \
--description="Custom service account for GKE nodes with minimal permissions"
# 3. 必要なロールを付与
PROJECT_ID=$(gcloud config get-value project)
SERVICE_ACCOUNT_EMAIL="gke-node-sa-[クラスター名]@${PROJECT_ID}.iam.gserviceaccount.com"
# ログ書き込み権限
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/logging.logWriter"
# メトリクス書き込み権限
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/monitoring.metricWriter"
# モニタリング情報の読み取り権限
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/monitoring.viewer"
# Artifact Registry読み取り権限(Artifact Registry使用時)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SERVICE_ACCOUNT_EMAIL}" \
--role="roles/artifactregistry.reader"
# 4. 新しいノードプールの作成
# 既存のノードプール設定を確認
gcloud container node-pools describe [既存ノードプール名] \
--cluster=[クラスター名] \
--zone=[ゾーン名] \
--format="yaml" > old-nodepool-config.yaml
# 新しいノードプールを作成
gcloud container node-pools create [新ノードプール名] \
--cluster=[クラスター名] \
--zone=[ゾーン名] \
--service-account=$SERVICE_ACCOUNT_EMAIL \
--scopes="<https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring,https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append>" \
--machine-type=[マシンタイプ] \
--num-nodes=[ノード数] \
--enable-autoscaling \
--min-nodes=[最小ノード数] \
--max-nodes=[最大ノード数] \
--enable-autorepair \
--enable-autoupgrade \
--shielded-secure-boot \
--shielded-integrity-monitoring \
--metadata disable-legacy-endpoints=true
# 5. ワークロードの移行(上記のkubectlコマンドを使用)
# 6. 古いノードプールの削除
gcloud container node-pools delete [古いノードプール名] \
--cluster=[クラスター名] \
--zone=[ゾーン名]
Terraformでの修復手順(Infrastructure as Code)
GKEクラスターでカスタムサービスアカウントを使用するTerraformコードと、主要な修正ポイントを説明します。
# カスタムサービスアカウントの作成
resource "google_service_account" "gke_node_sa" {
account_id = "gke-node-sa-${var.cluster_name}"
display_name = "GKE Node Service Account for ${var.cluster_name}"
description = "Custom service account for GKE nodes with minimal permissions"
project = var.project_id
}
# 必要最小限の権限を付与
locals {
node_sa_roles = [
"roles/logging.logWriter", # ログ書き込み
"roles/monitoring.metricWriter", # メトリクス書き込み
"roles/monitoring.viewer", # モニタリング情報の閲覧
"roles/artifactregistry.reader", # コンテナイメージの取得(Artifact Registry使用時)
# "roles/storage.objectViewer", # コンテナイメージの取得(Container Registry使用時)
]
}
resource "google_project_iam_member" "gke_node_sa_roles" {
for_each = toset(local.node_sa_roles)
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.gke_node_sa.email}"
}
# GKEクラスターの作成
resource "google_container_cluster" "primary" {
name = var.cluster_name
location = var.region
# デフォルトノードプールを削除(カスタムサービスアカウント付きのノードプールを後で作成)
remove_default_node_pool = true
initial_node_count = 1
# クラスターレベルのセキュリティ設定
enable_shielded_nodes = true
# Binary Authorization(オプション)
# enable_binary_authorization = true
# その他のクラスター設定
network = var.network
subnetwork = var.subnetwork
# セキュリティ設定
private_cluster_config {
enable_private_nodes = true
enable_private_endpoint = false
master_ipv4_cidr_block = var.master_ipv4_cidr_block
}
# Workload Identity の有効化(強く推奨)
workload_identity_config {
workload_pool = "${var.project_id}.svc.id.goog"
}
# ネットワークポリシー(オプション)
# network_policy {
# enabled = true
# }
}
# カスタムサービスアカウントを使用するノードプール
resource "google_container_node_pool" "primary_nodes" {
name = "${var.cluster_name}-node-pool"
location = var.region
cluster = google_container_cluster.primary.name
node_count = var.node_count
node_config {
preemptible = var.preemptible
machine_type = var.machine_type
# カスタムサービスアカウントを指定
service_account = google_service_account.gke_node_sa.email
# 必要最小限のスコープを設定
oauth_scopes = [
"<https://www.googleapis.com/auth/logging.write>",
"<https://www.googleapis.com/auth/monitoring>",
"<https://www.googleapis.com/auth/devstorage.read_only>",
"<https://www.googleapis.com/auth/servicecontrol>",
"<https://www.googleapis.com/auth/service.management.readonly>",
"<https://www.googleapis.com/auth/trace.append>"
]
# Workload Identity の設定
workload_metadata_config {
mode = "GKE_METADATA" # Workload Identityを有効化
}
# ノードのタイント設定(オプション)
# taint {
# key = "workload-type"
# value = "batch"
# effect = "NO_SCHEDULE"
# }
# セキュリティ設定
shielded_instance_config {
enable_secure_boot = true
enable_integrity_monitoring = true
}
metadata = {
disable-legacy-endpoints = "true"
}
labels = {
environment = var.environment
managed_by = "terraform"
}
tags = ["gke-node", var.cluster_name]
}
# アップグレード設定
management {
auto_repair = true
auto_upgrade = true
}
# ノードプールのオートスケーリング
autoscaling {
min_node_count = var.min_node_count
max_node_count = var.max_node_count
}
}
# Workload Identity用の設定(推奨)
# アプリケーション用のサービスアカウント(ノードSAとは別)
resource "google_service_account" "workload_identity_sa" {
account_id = "workload-identity-sa"
display_name = "Workload Identity Service Account"
description = "Service account for workload identity binding"
project = var.project_id
}
# Workload Identityバインディング
resource "google_service_account_iam_member" "workload_identity_binding" {
service_account_id = google_service_account.workload_identity_sa.name
role = "roles/iam.workloadIdentityUser"
member = "serviceAccount:${var.project_id}.svc.id.goog[${var.namespace}/${var.ksa_name}]"
}
# Kubernetesサービスアカウント
resource "kubernetes_service_account" "workload_identity" {
metadata {
name = var.ksa_name
namespace = var.namespace
annotations = {
"iam.gke.io/gcp-service-account" = google_service_account.workload_identity_sa.email
}
}
depends_on = [google_container_node_pool.primary_nodes]
}
# 出力値
output "cluster_name" {
value = google_container_cluster.primary.name
}
output "node_service_account" {
value = google_service_account.gke_node_sa.email
}
変数定義ファイル (variables.tf)
variable "project_id" {
description = "GCP Project ID"
type = string
}
variable "cluster_name" {
description = "GKE cluster name"
type = string
}
variable "region" {
description = "GCP region"
type = string
default = "us-central1"
}
variable "network" {
description = "VPC network name"
type = string
}
variable "subnetwork" {
description = "VPC subnetwork name"
type = string
}
variable "master_ipv4_cidr_block" {
description = "CIDR block for GKE master"
type = string
default = "172.16.0.0/28"
}
variable "node_count" {
description = "Number of nodes per zone"
type = number
default = 3
}
variable "machine_type" {
description = "Machine type for nodes"
type = string
default = "n1-standard-2"
}
variable "preemptible" {
description = "Use preemptible nodes"
type = bool
default = false
}
variable "min_node_count" {
description = "Minimum node count for autoscaling"
type = number
default = 1
}
variable "max_node_count" {
description = "Maximum node count for autoscaling"
type = number
default = 10
}
variable "environment" {
description = "Environment name"
type = string
default = "production"
}
variable "namespace" {
description = "Kubernetes namespace for workload identity"
type = string
default = "default"
}
variable "ksa_name" {
description = "Kubernetes service account name"
type = string
default = "workload-identity-ksa"
}
設定後の検証手順
カスタムサービスアカウントが正しく設定されていることを確認します:
# 1. ノードプールのサービスアカウント確認
gcloud container node-pools describe [ノードプール名] \
--cluster=[クラスター名] \
--zone=[ゾーン名] \
--format="value(config.serviceAccount)"
# 2. ノード上で実行中のPodのサービスアカウント確認
kubectl run test-pod --image=google/cloud-sdk:slim --rm -it --restart=Never -- \
gcloud auth list
# 3. ノードのメタデータからサービスアカウント確認
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.providerID}{"\n"}{end}' | \
while read node provider; do
instance=$(echo $provider | cut -d'/' -f5)
zone=$(echo $provider | cut -d'/' -f4)
echo "Node: $node"
gcloud compute instances describe $instance --zone=$zone \
--format="value(serviceAccounts[0].email)"
done
Workload Identityを使用すべき理由
Workload Identityは、GKEにおけるセキュリティ設定のベストプラクティスとなります。
- ノードレベルの権限を最小限にする: ノードは基本的な動作に必要な権限のみ保持
- Pod単位の細かい権限制御を行う: 各アプリケーションに必要な権限のみを付与
- サービスアカウントキー利用しない: キー管理の複雑さとリスクを排除
- 監査ログがより明確になる: どのPodがどのGCPリソースにアクセスしたか明確に追跡
ベストプラクティス
- Workload Identityの使用:
- ノードレベルのサービスアカウントは最小限に保ち、アプリケーション固有の権限はWorkload Identityで管理
- 各アプリケーションごとに専用のKubernetesサービスアカウントとGCPサービスアカウントを作成
- 監査ログの活用:
- Cloud Audit Logsでサービスアカウントの使用状況を監視
- 異常なアクセスパターンを検出するアラートを設定
- 定期的な権限レビュー:
- 定期的にサービスアカウントの権限をレビュー
- 不要になった権限は即座に削除
- Policy Analyzerを使用して過剰な権限を特定
- サービスアカウントキーの管理:
- サービスアカウントキーの作成は原則禁止
- やむを得ず作成する場合は90日ごとにローテーション
- キーの使用状況を監視し、未使用のキーは削除
- 環境ごとの分離:
- 開発、ステージング、本番環境で異なるサービスアカウントを使用
- 環境間でのサービスアカウントの共有を禁止
まとめ
この記事では、GKEノードでカスタムサービスアカウントを使用する設定手順について、リスクと対策を解説しました。
重要なポイント
- デフォルトサービスアカウントは重大なセキュリティリスク: Editor権限によりプロジェクト全体への広範なアクセスが可能
- 移行は必須だが計画的に: ノードプールの再作成が必要なため、ダウンタイムを考慮した計画が重要
- Workload Identityとの併用が理想: ノードレベルは最小権限、アプリケーションレベルで細かい制御するのが運用上はベストとなります。
- 継続的な監視とレビュー: 権限の定期的な見直しと監査ログの活用
デフォルトのCompute Engineサービスアカウントからカスタムサービスアカウントへの移行は、GKEセキュリティ強化の基本的かつ重要なステップです。最小権限の原則に従い、必要な権限のみを付与することで、セキュリティインシデントの影響を大幅に削減できます。
この問題の検出は弊社が提供するSecurifyのCSPM機能で簡単に検出及び管理する事が可能です。 運用が非常に楽に出来る製品になっていますので、ぜひ興味がある方はお問い合わせお待ちしております。 最後までお読みいただきありがとうございました。この記事が皆さんの役に立てば幸いです。
CSPMについてはこちらで解説しております。併せてご覧ください。
