BigQueryでSensitive Data Protectionを使った機密データの自動検出と分類方法

このブログシリーズ 「クラウドセキュリティ 実践集」 では、一般的なセキュリティ課題を取り上げ、「なぜ危険なのか?」 というリスクの解説から、 「どうやって直すのか?」 という具体的な修復手順(コンソール、gcloud CLI、Terraformなど)まで、分かりやすく解説します。
この記事では、BigQueryのすべてのデータが分類されていないについて、リスクと対策を解説します。

ポリシーの説明
BigQueryテーブルに含まれる機密データを保護するため、Google CloudのSensitive Data Protectionなどのツールを使用して、組織全体のすべてのBigQueryデータを自動的に検出し、分類し、監視することが重要です。データ分類により、個人識別情報(PII)、クレジットカード番号、社会保障番号などの機密データがどこに存在するかを把握し、適切なセキュリティ対策を実施できます。これは、データガバナンスの基本的な要件であり、多くのコンプライアンス規制で要求される重要な管理策です。
Sensitive Data Protectionで検出可能な情報タイプ
| カテゴリ | 情報タイプ例 | 説明 |
|---|---|---|
| 個人識別情報 | EMAIL_ADDRESS, PHONE_NUMBER, PERSON_NAME | 個人を特定可能な基本情報 |
| 金融情報 | CREDIT_CARD_NUMBER, IBAN_CODE, SWIFT_CODE | 金融取引に関する機密情報 |
| 医療情報 | MEDICAL_RECORD_NUMBER, FDA_CODE | 医療・健康に関する情報 |
| 日本固有 | JAPAN_INDIVIDUAL_NUMBER, JAPAN_PASSPORT, JAPAN_DRIVER_LICENSE_NUMBER | マイナンバー、パスポート、運転免許証番号 |
| 政府ID | US_SOCIAL_SECURITY_NUMBER, UK_NATIONAL_INSURANCE_NUMBER | 各国の政府発行ID |
ビジネス要件としてセンシティブなデータを扱う場合においては有効化しておきましょう。
修復方法
コンソールでの修復手順
Google Cloud コンソールを使用して、Sensitive Data Protectionを設定し、BigQueryデータを自動的に分類します。
- Sensitive Data Protectionの有効化
- Google Cloud Consoleにログインします
- ナビゲーションメニューから「セキュリティ」→「Sensitive Data Protection」を選択します
- 初回アクセス時は、APIを有効化するプロンプトが表示される場合があります

- 検査テンプレートの作成
- 「構成」→「テンプレート」→「検査」タブを選択します
- 「テンプレートを作成」をクリックします

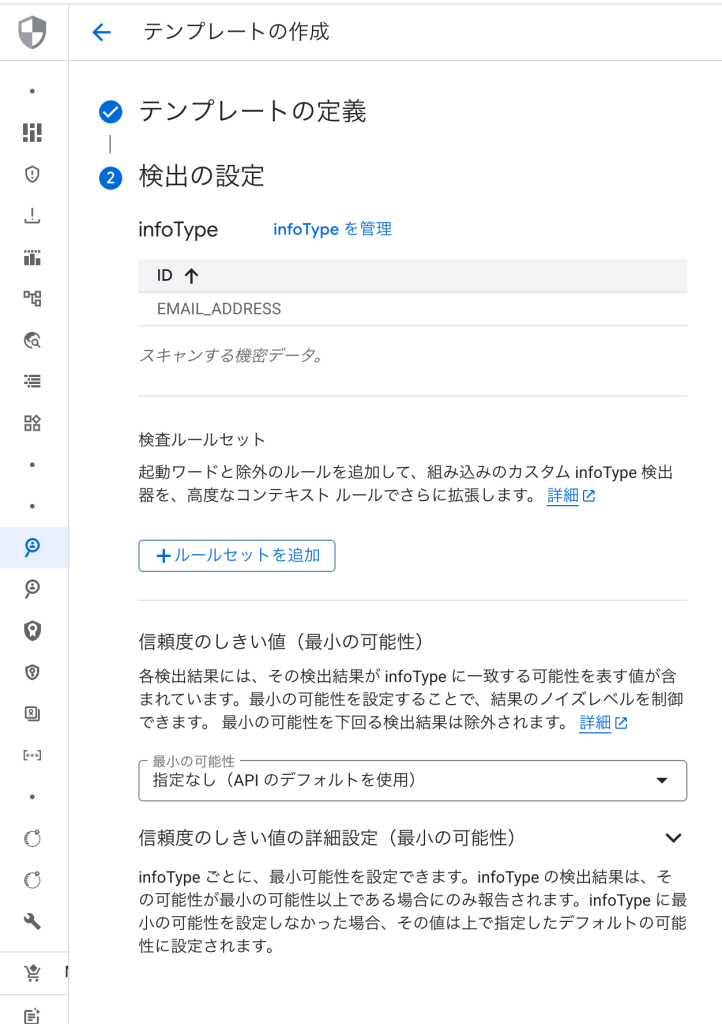
- テンプレート名(例:
bigquery-data-classification)を入力します - 「検出項目」セクションで、検出したい情報タイプを選択します:
- 個人識別情報(名前、住所、電話番号、メールアドレス)
- 金融情報(クレジットカード番号、銀行口座番号)
- 医療情報(診断情報、処方箋情報)
- 政府発行ID(社会保障番号、パスポート番号)

- 「作成」をクリックします
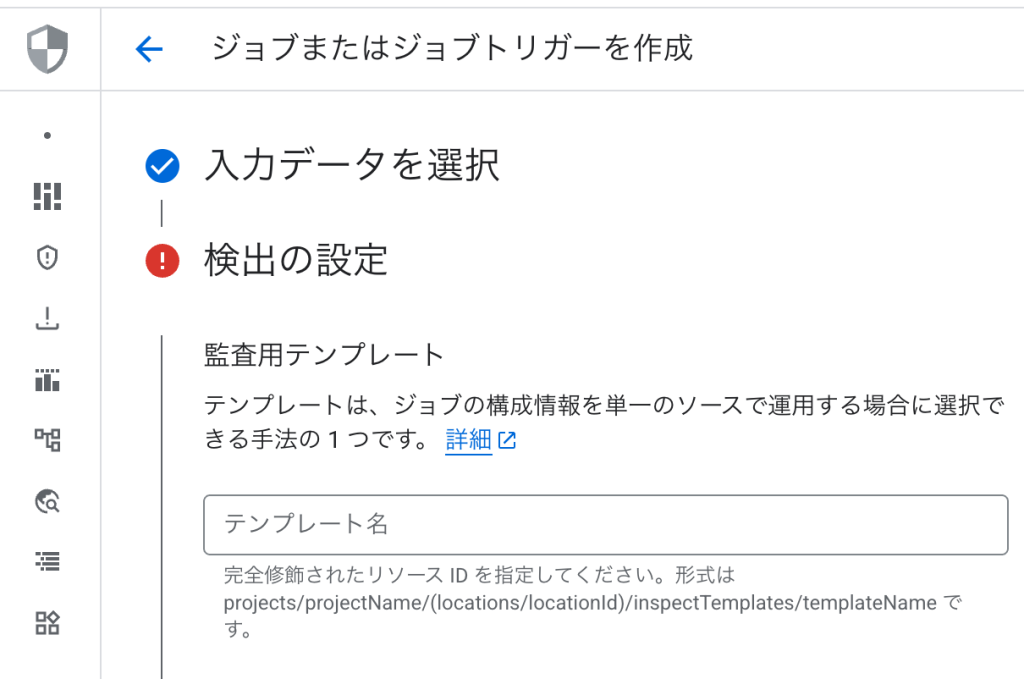
- BigQueryデータのスキャンジョブ作成
- 「機密データの保護」→「検査」タブを選択します
- 「ジョブとジョブトリガーを作成」をクリックします
- 入力ソースとして「BigQuery」を選択します
- スキャン対象を選択:
- プロジェクト全体
- 特定のデータセット
- 特定のテーブル
- 作成した検査テンプレートを選択します

- 「アクション」セクションで以下を設定:
- BigQueryに結果を保存
- Pub/Subに通知を送信(オプション)
- 定期スキャンの設定
- 「スケジュール」セクションで定期実行を設定します
- 推奨:日次または週次でのスキャン
- トリガー条件を設定(新規テーブル作成時など)
- データカタログとの統合
- Data Catalogに移動します
- ポリシータグ分類を作成:
- 「ポリシータグ」→「分類を作成」
- 分類名(例:
data-sensitivity)を入力 - タグを作成(例:
public、internal、confidential、restricted)
- 分類結果の確認とタグ付け
- Sensitive Data Protectionの結果を確認します
- 検出された機密データを含むテーブルにData Catalogでタグを付けます
- 各テーブルの機密性レベルに応じて適切なポリシータグを適用します
Terraformでの修復手順
Sensitive Data Protectionを使用してBigQueryデータを自動的に分類するTerraformコードと、主要な修正ポイントを説明します。
# Sensitive Data Protection APIの有効化
resource "google_project_service" "dlp_api" {
project = var.project_id
service = "dlp.googleapis.com"
disable_on_destroy = false
}
# 検査テンプレートの作成
resource "google_data_loss_prevention_inspect_template" "data_classification" {
parent = "projects/${var.project_id}/locations/global"
display_name = "BigQuery Data Classification Template"
description = "BigQueryデータの機密情報を検出・分類するためのテンプレート"
inspect_config {
# 検出する情報タイプ
info_types {
name = "EMAIL_ADDRESS"
}
info_types {
name = "PHONE_NUMBER"
}
info_types {
name = "CREDIT_CARD_NUMBER"
}
info_types {
name = "JAPAN_INDIVIDUAL_NUMBER" # マイナンバー
}
info_types {
name = "JAPAN_PASSPORT"
}
info_types {
name = "JAPAN_DRIVER_LICENSE_NUMBER"
}
# カスタム情報タイプの定義
custom_info_types {
info_type {
name = "EMPLOYEE_ID"
}
regex {
pattern = "EMP[0-9]{6}"
}
likelihood = "LIKELY"
}
# 最小一致確率
min_likelihood = "POSSIBLE"
# 検査ルール
rule_set {
info_types {
name = "EMAIL_ADDRESS"
}
rules {
exclusion_rule {
regex {
pattern = ".*@example\\.com" # テストデータを除外
}
matching_type = "MATCHING_TYPE_FULL_MATCH"
}
}
}
# 検査制限
limits {
max_findings_per_item = 100
max_findings_per_request = 1000
}
}
depends_on = [google_project_service.dlp_api]
}
# BigQuery結果保存用のデータセット
resource "google_bigquery_dataset" "dlp_findings" {
dataset_id = "dlp_findings"
friendly_name = "DLP Findings Dataset"
description = "Sensitive Data Protectionの検査結果を保存するデータセット"
location = var.region
# データ保持期間(30日)
default_table_expiration_ms = 2592000000
access {
role = "OWNER"
user_by_email = var.dlp_admin_email
}
labels = {
purpose = "data-classification"
}
}
# Data Catalogのタクソノミー(分類体系)
resource "google_data_catalog_taxonomy" "data_classification" {
provider = google-beta
region = var.region
display_name = "Data Classification Taxonomy"
description = "機密データの分類体系"
activated_policy_types = ["FINE_GRAINED_ACCESS_CONTROL"]
}
resource "google_data_catalog_policy_tag" "sensitivity_levels" {
provider = google-beta
for_each = toset(["public", "internal", "confidential", "restricted"])
taxonomy = google_data_catalog_taxonomy.data_classification.id
display_name = title(each.key)
description = "Data classified as ${each.key}"
# 各レベルの詳細説明
dynamic "fields" {
for_each = {
public = "一般公開可能なデータ"
internal = "組織内部でのみ共有可能なデータ"
confidential = "機密データ(アクセス制限必要)"
restricted = "高度機密データ(厳格なアクセス制御必要)"
}
content {
field_value = {
string_value = fields.value
}
}
}
}
# BigQueryスキャンジョブの設定
resource "google_data_loss_prevention_job_trigger" "bigquery_scan" {
parent = "projects/${var.project_id}/locations/global"
display_name = "BigQuery Daily Data Classification Scan"
description = "BigQueryデータの日次機密情報スキャン"
triggers {
schedule {
recurrence_period_duration = "86400s" # 24時間ごと
}
}
inspect_job {
inspect_template_name = google_data_loss_prevention_inspect_template.data_classification.id
storage_config {
big_query_options {
table_reference {
project_id = var.project_id
# プロジェクト内のすべてのデータセットをスキャン
}
# サンプリング設定
sample_method = "RANDOM_START"
rows_limit_percent = 10 # 10%のサンプリング
# 除外パターン
excluded_fields {
name = "*.created_at"
}
excluded_fields {
name = "*.updated_at"
}
}
}
# 検査結果の保存先
actions {
save_findings {
output_config {
table {
project_id = var.project_id
dataset_id = google_bigquery_dataset.dlp_findings.dataset_id
table_id = "classification_findings_${formatdate("YYYYMMDD", timestamp())}"
}
}
}
# Pub/Sub通知
pub_sub {
topic = google_pubsub_topic.dlp_notifications.id
}
}
}
status = "HEALTHY"
depends_on = [
google_data_loss_prevention_inspect_template.data_classification,
google_bigquery_dataset.dlp_findings
]
}
# 通知用Pub/Subトピック
resource "google_pubsub_topic" "dlp_notifications" {
name = "dlp-classification-notifications"
labels = {
purpose = "dlp-alerts"
}
}
# Cloud Functionsで自動タグ付け
resource "google_cloudfunctions_function" "auto_tagging" {
name = "dlp-auto-tagging"
description = "DLP検出結果に基づいて自動的にData Catalogタグを付与"
runtime = "python39"
available_memory_mb = 256
source_archive_bucket = google_storage_bucket.functions_bucket.name
source_archive_object = google_storage_bucket_object.function_code.name
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = google_pubsub_topic.dlp_notifications.name
}
entry_point = "process_dlp_findings"
environment_variables = {
PROJECT_ID = var.project_id
TAXONOMY_ID = google_data_catalog_taxonomy.data_classification.id
}
}
# モニタリングアラート
resource "google_monitoring_alert_policy" "high_risk_data_detected" {
display_name = "High Risk Data Detected in BigQuery"
combiner = "OR"
conditions {
display_name = "Restricted data found"
condition_threshold {
filter = <<-EOT
resource.type="bigquery_project"
metric.type="logging.googleapis.com/user/dlp_restricted_data_count"
EOT
duration = "0s"
comparison = "COMPARISON_GT"
threshold_value = 0
aggregations {
alignment_period = "300s"
per_series_aligner = "ALIGN_SUM"
}
}
}
notification_channels = var.notification_channels
documentation {
content = "高リスクの機密データがBigQueryで検出されました。直ちに確認し、適切なアクセス制御を実施してください。"
}
}
# データ分類ダッシュボード用のビュー
resource "google_bigquery_table" "classification_summary_view" {
dataset_id = google_bigquery_dataset.dlp_findings.dataset_id
table_id = "classification_summary"
view {
query = <<-SQL
WITH latest_findings AS (
SELECT
location.content_locations[0].container_name as table_name,
info_type.name as info_type,
COUNT(*) as finding_count,
MAX(create_time) as last_detected
FROM
`${var.project_id}.${google_bigquery_dataset.dlp_findings.dataset_id}.classification_findings_*`
WHERE
_TABLE_SUFFIX >= FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY))
GROUP BY
table_name, info_type
)
SELECT
table_name,
ARRAY_AGG(STRUCT(info_type, finding_count)) as detected_types,
MAX(last_detected) as last_scan_time,
CASE
WHEN MAX(CASE WHEN info_type IN ('CREDIT_CARD_NUMBER', 'JAPAN_INDIVIDUAL_NUMBER') THEN 1 ELSE 0 END) = 1 THEN 'restricted'
WHEN MAX(CASE WHEN info_type IN ('EMAIL_ADDRESS', 'PHONE_NUMBER') THEN 1 ELSE 0 END) = 1 THEN 'confidential'
WHEN MAX(CASE WHEN info_type IN ('EMPLOYEE_ID') THEN 1 ELSE 0 END) = 1 THEN 'internal'
ELSE 'public'
END as suggested_classification
FROM
latest_findings
GROUP BY
table_name
SQL
use_legacy_sql = false
}
}
# 変数定義
variable "project_id" {
description = "GCPプロジェクトID"
type = string
}
variable "region" {
description = "リージョン"
type = string
default = "asia-northeast1"
}
variable "dlp_admin_email" {
description = "DLP管理者のメールアドレス"
type = string
}
variable "notification_channels" {
description = "アラート通知チャンネル"
type = list(string)
default = []
}
# アウトプット
output "inspect_template_id" {
description = "作成された検査テンプレートのID"
value = google_data_loss_prevention_inspect_template.data_classification.id
}
output "classification_dataset_id" {
description = "分類結果保存用データセットのID"
value = google_bigquery_dataset.dlp_findings.dataset_id
}
最後に
この記事では、BigQueryでSensitive Data Protectionを使った機密データの自動検出と分類方法について、リスクと対策を解説しました。
この問題の検出は弊社が提供するSecurifyのCSPM機能で簡単に検出及び管理する事が可能です。 運用が非常に楽に出来る製品になっていますので、ぜひ興味がある方はお問い合わせお待ちしております。 最後までお読みいただきありがとうございました。この記事が皆さんの役に立てば幸いです。
CSPMについてはこちらで解説しております。併せてご覧ください。
