ElastiCache for Redis レプリケーショングループの自動フェイルオーバー有効化設定手順

このブログシリーズ 「クラウドセキュリティ 実践集」 では、一般的なセキュリティ課題を取り上げ、「なぜ危険なのか?」 というリスクの解説から、 「どうやって直すのか?」 という具体的な修復手順(コンソール、AWS CLI、Terraformなど)まで、分かりやすく解説します。
この記事では、ElastiCache for Redisレプリケーショングループの自動フェイルオーバー有効化について、リスクと対策を解説します。

ポリシーの説明
ElastiCache for Redisのレプリケーショングループにおいて、自動フェイルオーバー機能は高可用性を実現する重要な設定です。自動フェイルオーバーが有効な場合、プライマリノードに障害が発生すると、システムが自動的にレプリカノードをプライマリに昇格させ、サービスの継続性を保ちます。この機能により、手動介入なしにダウンタイムを最小限に抑制できます。
前提条件
- Redis 2.8.6以降(Redis 7.0以降を推奨)
- 少なくとも1つのレプリカノード(2つ以上を強く推奨)
- レプリケーショングループとして構成されていること(スタンドアロンクラスターでは利用不可)
修復方法
コンソールでの修復手順
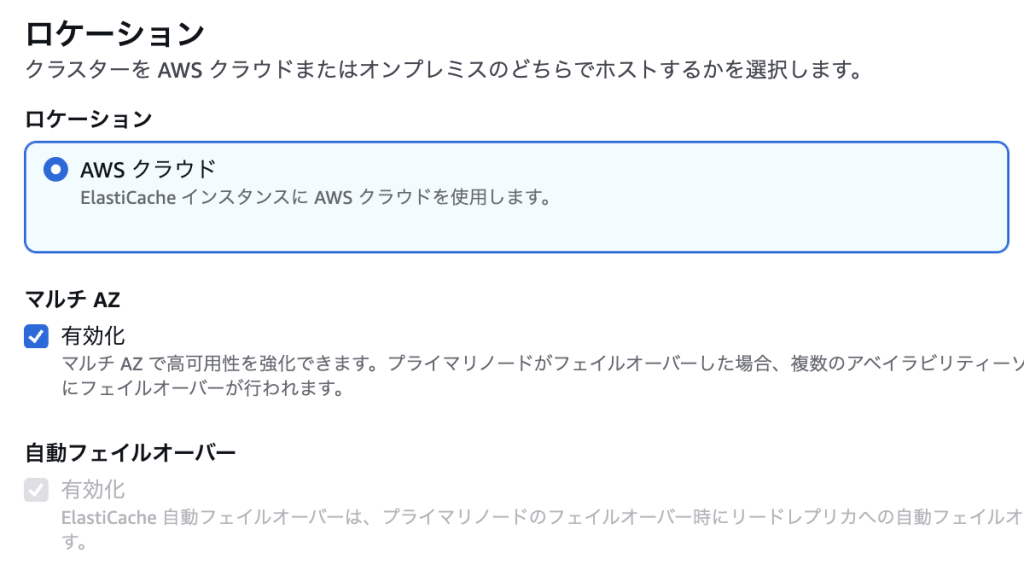
AWSのコンソールを使用して、ElastiCache for Redisの自動フェイルオーバーを有効化します。
既存のレプリケーショングループに対する設定手順:
- AWS Management Console にログインし、ElastiCacheサービスに移動します。
- 左側のナビゲーションペインから 「Redis OSS キャッシュ」 を選択します。
- 対象のレプリケーショングループを選択し、名前をクリックして詳細画面を開きます。
- 上部の 「アクション」 ボタンをクリックし、「変更」 を選択します。
- 変更画面で以下の設定を行います:
- 「Multi-AZ」 セクションで 「自動フェイルオーバーを有効化」 にチェックを入れます
- 「マルチAZ」 オプションも併せて有効化を推奨
- 「レプリカ数」 が少なくとも1以上であることを確認します
- 開発環境:1レプリカ
- 本番環境:2レプリカ以上を強く推奨
- ミッションクリティカル:3レプリカ以上を検討
- 「変更の適用タイミング」 を選択します:
- 「今すぐ適用」:即座に変更を適用
- 接続断:数秒から最大30秒程度
- 開発環境では選択可
- 「次のメンテナンスウィンドウ中」:設定されたメンテナンス時間帯に適用
- 本番環境では強く推奨
- 事前にアプリケーションチームへの通知が必要
- 「今すぐ適用」:即座に変更を適用
- 「変更をプレビュー」 をクリックして、変更内容を確認します。
- 問題がなければ 「変更する」 をクリックして適用します。
新規レプリケーショングループ作成時の設定:
- ElastiCacheコンソールで 「作成」 ボタンをクリックします。
- 「Redis」 を選択し、以下の設定を行います:
- 「クラスターモード」 を選択(有効/無効)
- 「Multi-AZ」 セクションで 「自動フェイルオーバーを有効化」 をオンにします
- 「レプリカ数」 を1以上に設定します

- その他必要な設定(ノードタイプ、ネットワーク、セキュリティ等)を行い、作成を完了します。
Terraformでの修復手順
ElastiCache for Redisの自動フェイルオーバーを有効にするTerraformコードと、主要な修正ポイントを説明します。
# Variables
variable "environment" {
description = "Environment name"
type = string
validation {
condition = contains(["dev", "staging", "prod"], var.environment)
error_message = "Environment must be dev, staging, or prod."
}
}
variable "enable_automatic_failover" {
description = "Enable automatic failover for high availability"
type = bool
default = true
}
resource "aws_elasticache_replication_group" "redis_cluster" {
replication_group_id = "${var.environment}-redis-cluster"
description = "Redis cluster with automatic failover enabled for ${var.environment}"
# 自動フェイルオーバーの有効化(重要)
automatic_failover_enabled = var.enable_automatic_failover
multi_az_enabled = var.enable_automatic_failover # 自動フェイルオーバーと連動
# ノード設定(環境別に最適化)
node_type = var.environment == "prod" ? "cache.r7g.large" : "cache.t3.small"
engine = "redis"
engine_version = "7.0"
port = 6379
parameter_group_name = aws_elasticache_parameter_group.redis.name
# レプリケーション設定(環境別)
num_node_groups = var.cluster_mode_enabled ? 3 : 1 # クラスターモード時は3シャード
replicas_per_node_group = var.environment == "prod" ? 2 : 1 # 本番は2レプリカ必須
# セキュリティ設定
at_rest_encryption_enabled = true
transit_encryption_enabled = true
auth_token_enabled = true
auth_token = var.redis_auth_token
# バックアップ設定(自動フェイルオーバーと併用推奨)
snapshot_retention_limit = var.environment == "prod" ? 30 : 7
snapshot_window = "03:00-05:00" # UTC
maintenance_window = "sun:05:00-sun:07:00" # UTC
# 通知設定(重要)
notification_topic_arn = aws_sns_topic.redis_alerts.arn
# ネットワーク設定
subnet_group_name = aws_elasticache_subnet_group.redis.name
security_group_ids = [aws_security_group.redis.id]
# 変更の即時適用
apply_immediately = false
tags = {
Name = "${var.environment}-redis-cluster"
Environment = var.environment
AutoFailover = var.enable_automatic_failover ? "enabled" : "disabled"
ManagedBy = "terraform"
}
# ライフサイクル管理
lifecycle {
prevent_destroy = var.environment == "prod" ? true : false
}
}
# パラメータグループ(フェイルオーバー最適化)
resource "aws_elasticache_parameter_group" "redis" {
family = "redis7"
name = "${var.environment}-redis-params"
# フェイルオーバー時のタイムアウト設定
parameter {
name = "timeout"
value = "300" # 5分(デフォルトは0で無制限)
}
# レプリケーション遅延の監視
parameter {
name = "repl-timeout"
value = "60" # 60秒後にレプリカを切断
}
# クライアント出力バッファ制限
parameter {
name = "client-output-buffer-limit-replica-soft-limit"
value = "8388608" # 8MB
}
}
# サブネットグループの定義
resource "aws_elasticache_subnet_group" "redis" {
name = "redis-subnet-group"
subnet_ids = var.private_subnet_ids
tags = {
Name = "Redis Subnet Group"
}
}
# セキュリティグループの定義
resource "aws_security_group" "redis" {
name_prefix = "${var.environment}-redis-sg-"
vpc_id = var.vpc_id
ingress {
from_port = 6379
to_port = 6379
protocol = "tcp"
security_groups = [var.application_security_group_id]
description = "Allow Redis access from application"
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow all outbound traffic"
}
tags = {
Name = "${var.environment}-redis-sg"
Environment = var.environment
}
}
# SNSトピック(フェイルオーバー通知用)
resource "aws_sns_topic" "redis_alerts" {
name = "${var.environment}-redis-failover-alerts"
tags = {
Name = "${var.environment}-redis-alerts"
Purpose = "Automatic failover notifications"
}
}
# SNSサブスクリプション
resource "aws_sns_topic_subscription" "redis_email" {
topic_arn = aws_sns_topic.redis_alerts.arn
protocol = "email"
endpoint = var.alert_email
}
# CloudWatchアラーム(フェイルオーバー監視)
resource "aws_cloudwatch_metric_alarm" "redis_primary_link_health" {
alarm_name = "${var.environment}-redis-primary-link-health"
comparison_operator = "LessThanThreshold"
evaluation_periods = 2
metric_name = "ReplicationLag"
namespace = "AWS/ElastiCache"
period = 60
statistic = "Maximum"
threshold = 30 # 30秒以上の遅延でアラート
alarm_description = "Alert when replication lag is too high"
alarm_actions = [aws_sns_topic.redis_alerts.arn]
dimensions = {
ReplicationGroupId = aws_elasticache_replication_group.redis_cluster.id
}
}
主要な修正ポイント:
automatic_failover_enabled = true:この設定が最も重要です。必ずtrueに設定してください。multi_az_enabled = true:Multi-AZを有効化することで、異なるアベイラビリティーゾーンにノードが配置されます。replicas_per_node_group:最低1以上、推奨は2以上のレプリカを設定します。これにより、プライマリノード障害時の選択肢が増えます。- セキュリティ設定の併用:自動フェイルオーバーと併せて、暗号化(at_rest/transit)と認証(auth_token)も有効化することを推奨します。
apply_immediately:本番環境ではfalseに設定し、メンテナンスウィンドウ中に適用することを推奨します。- 監視とアラート:CloudWatchアラームとSNS通知を設定し、フェイルオーバー発生時に即座に通知を受け取れるようにします。
- パラメータチューニング:
timeoutやrepl-timeoutを適切に設定し、フェイルオーバーの応答性を最適化します。
最後に
この記事では、ElastiCache for Redisレプリケーショングループの自動フェイルオーバー有効化について、リスクと対策を解説しました。
自動フェイルオーバーは単なる設定変更ではなく、高可用性アーキテクチャの重要な要素です。適切に設定された自動フェイルオーバーは、年間99.99%(Four Nines)の可用性を実現し、計画外のダウンタイムを年間52分以内に抑えることができます。特に、ミッションクリティカルなアプリケーションや24時間365日のサービス提供が求められる環境では、この設定は必須といえるでしょう。
実装時は、レプリカ数の適正化、Multi-AZの活用、定期的なフェイルオーバーテスト、そして適切な監視とアラートの設定を組み合わせることで、真に信頼性の高いRedisクラスターを構築できます。
この問題の検出は弊社が提供するSecurifyのCSPM機能で簡単に検出及び管理する事が可能です。 運用が非常に楽に出来る製品になっていますので、ぜひ興味がある方はお問い合わせお待ちしております。 最後までお読みいただきありがとうございました。この記事が皆さんの役に立てば幸いです。
CSPMについてはこちらで解説しております。併せてご覧ください。
